
Analýza dat v neurologii
Autoři:
L. Dušek; T. Pavlík; J. Jarkovský
![]() ; J. Koptíková
; J. Koptíková
Působiště autorů:
Institut biostatistiky a analýz, Masarykova univerzita, Brno
Vyšlo v časopise:
Cesk Slov Neurol N 2015; 78/111(3): 367-369
Kategorie:
Okénko statistika
LI. Yuleovo Q – užitečný nástroj pro srovnávání různých odhadů poměru šancí
Minulý díl seriálu jsme zakončili poznámkou o velkém číselném rozsahu možných hodnot poměru šancí (OR), který může být problémem při vzájemném srovnávání výstupů různých studií. Připomeňme, že poměr šancí probíráme z různých pohledů od dílu 35 našeho seriálu jako velmi významný ukazatel míry vztahu „expozice– účinek“ v observačních studiích. OR počítáme podle vztahu uvedeného pod následující nejjednodušší možnou tabulkou četností 2 × 2 (tab. 1). Jelikož v polích tabulky a– d jsou uvedeny četnosti dané vzorkovacím plánem studie, může odhad OR nabývat jakékoli hodnoty od 0 do nekonečna. V tomto dílu seriálu se pokusíme odpovědět na otázku, která v této souvislosti jistě mnohé čtenáře napadla. A sice, zda existují nějaké ukazatele umožňující snadné srovnávání odhadů poměru šancí publikovaných různými studiemi, aniž musíme provádět složité statistické testy?
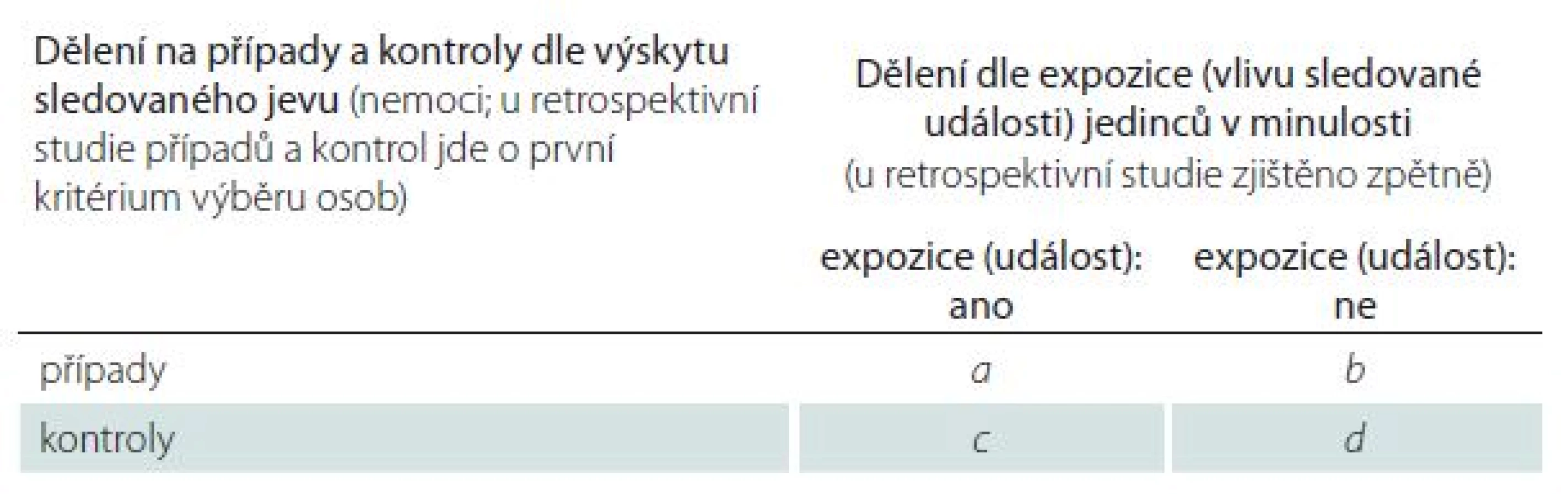
Nespornou výhodou poměru šancí je jistě to, že v rámci jedné práce umožňuje vzájemně srovnat míru asociace více faktorů s cílovým parametrem; číselné vyjádření OR včetně intervalu spolehlivosti je velice instruktivní, ať již v tabulkách nebo grafech. O dost obtížněji se však srovnávají odhady OR publikované různými studiemi, neboť jejich hodnota závisí na mnoha faktorech, od velikosti vzorku až po statistickou techniku, která je pro odhad použita. Hodnoty OR také mohou u problematicky rozložených vzorků nabývat až extrémně vysokých hodnot. Zatímco spodní hranice možných hodnot OR je jasně ohraničena nulou, horní hranice prakticky neexistuje.
V příkladu 1 uvádíme několik případů dokládajících číselnou heterogenitu odhadů OR.

V praxi takto můžeme čelit úkolu znázornit ve srovnávacím grafu či tabulce hodnoty OR, které se mohou lišit až o dva řády. Takové srovnání v grafu samozřejmě postrádá smysl. Odhady OR lze sice zlogaritmovat (log(OR)) a tak je snáze vykreslit do jednoho grafu, ale takto transformované hodnoty jsou obtížně interpretovatelné a čitelné. Pro srovnání různých odhadů OR je možné také využít statistické testy (viz díl 37 seriálu), které sice pomohou určit, zda je rozdíl mezi různými odhady OR statisticky významný, ale nenabídnou nám lehce použitelnou škálu pro kvantitativní porovnání různých hodnot.
Tento problém má naštěstí velmi snadné řešení a tím je transformace odhadu OR do statistiky zvané Yuleovo Q (Yule’s Q). Je nazvána po svém autorovi, skotském statistikovi jménem George Udny Yule (1871– 1951). Jde v podstatě o transformaci převádějící hodnoty OR do jasně čitelné škály od – 1 do +1, což z ní činí velmi užitečný nástroj pro vzájemné srovnávání a řazení i číselně velmi odlišných odhadů OR.
Yuleovo Q vypočítáme přímo z odhadu OR velmi jednoduše podle vztahu:
Q = (OR – 1)/ (OR + 1),
nebo alternativně přímo z čtyřpolní tabulky četností:
Q = (bc – ad)/ (bc + ad).
Yuleovo Q se řadí mezi tzv. kontingenční koeficienty, kterým jsme věnovali velký prostor v díle 21 našeho seriálu. Statistika Q má řadu zajímavých vlastností. Například nemá žádné modelové statistické rozdělení („distribution-free statistics“) a nezávisí na marginálních rozděleních četností ve zdrojové tabulce (Awosami et al, 1999; Warrens, 2008). Jeho hlavním omezením je, že znaky dávané do vzájemné asociace musí být povinně binarizovány, neboť Yuleovo Q patří mezi ukazatele určené pouze pro tabulky četností 2 × 2. Vynásobíme‑li absolutní hodnotu Q konstantou 100, můžeme jej interpretovat v procentech. Takto zjednodušeně řečeno vyjadřuje relativní redukci chyby, kterou děláme, když z jednoho znaku v tabulce četností predikujeme hodnoty znaku druhého (Baddie a Fred, 1995).
Jak již bylo řečeno, hlavním přínosem Yuleova Q je standardizace hodnot OR do intervalu < – 1; +1 >. Hodnoty Q blízké nule znamenají malou závislost asociovaných znaků a naopak hodnoty blízké – 1 nebo +1 znamenají velmi silnou závislost. V literatuře můžeme nalézt i podrobnější dělení škály pro Yuleovo Q, které mohou být interpretačně velmi užitečné. Jako příklad uvádíme škálu pro Q publikovanou Bohrnstedtem a Knokem v roce 1988:
- hodnoty Q 0– 0,24: žádný nebo zanedbatelný vztah proměnných,
- hodnoty Q 0,25– 0,49: slabý vztah,
- hodnoty Q 0,50– 0,74: středně silný vztah,
- hodnoty Q 0,75– 1,00: velmi silný vztah.
Velkou výhodou výpočtu Q je, že jej lze aplikovat na již publikované odhady OR. Tedy bez znalosti primárních dat a bez dalších předpokladů o rozdělení zapojených statistik. Ukázku transformace i velmi rozdílných hodnot OR pomocí Yuleova Q přináší příklad 2. Je patrné, že aplikace tohoto jednoduchého nástroje značně zvyšuje čitelnost a usnadňuje interpretaci rozdílných odhadů OR.

I u statistiky Q se můžeme opřít o hodnocení její významnosti, což vzhledem k jejím hodnotám znamená testovat platnost hypotézy Q = 0 (tedy hypotézy neexistence závislosti „expozice–účinek“ v tabulce četností). Statistický test využívá standardizovaného normálního rozdělení (testová statistika Z). Příklad 3 je ukázkou tohoto testu.

Je zajímavé, jak se statistický ukazatel starší více než 100 let stále užitečně uplatňuje v prezentování výsledků současného výzkumu. Nadto i v relativně soudobé literatuře nalezneme metodické práce rozšiřující informační potenciál nebo usilující o nové aplikace Yuleova Q. Jako příklad můžeme uvést práci Lipsitze a Fitzmaurice z roku 1994 zaměřenou na uplatnění Q statistiky při analýze vícerozměrných binárních dat. Statistika Q dále nalézá velké uplatnění v moderní analýze sociologických průzkumů a v hodnocení edukačních programů, kde je zkoumání vlivu různých prediktorů na efektivitu vzdělávání velmi časté (Adeyemi, 2003).
Pozn.: Určitou modifikací statistiky Q je tzv. Yuleovo Y, které počítáme dle následujícího vztahu: Y = (√OR – 1)/ (√OR + 1). Statistika Y je také nazývána koeficient koligace, zatímco statistika Q je nazývána koeficient asociace. Rozdíl je zde v uplatnění druhé odmocniny odhadu OR. Rovněž škála statistiky Y nabývá hodnot od – 1 do +1, v tomto smyslu není při jejím uplatnění žádný rozdíl od Q. Yuleovo Y transformuje hodnoty OR konzervativněji než statistika Q.
doc. RNDr. Ladislav Dušek, Ph.D.
Institut biostatistiky a analýz
MU, Brno
e‑mail: dusek@iba.muni.cz
Zdroje
1. Adeyemi TO. Statistical Techniques for educational research. Lagos: Universal Publisher 2003.
2. Awosami RO, Olopoenia S, Adeyefa O. Economics for senior secondary school certificate examinations. Ibadan: Spectrum Books Ltd. 1999.
3. Baddie E, Fred H. Advantages in social research: data analysis using SPSS for Windows the thousands oaks. California: Pine Forge Press a Sage Publications Company 1995.
4. Bohrnstedt GW, Knoke D. Statistics for social data analysis. 2nd ed. Itasca, Illinois: F.E. Peacock Publishers, Inc. 1988.
5. Lipsitz RS, Fitzmaurice G. An extension of Yule‘s Q to multivariate binary data. Biometrics 1994; 50(3): 847– 852.
6. Yule GU. On the methods of measuring association between two attributes. Journal of the Royal Statistical Society 1912; LXXV: 579– 652.
7. Warrens M. On association coefficients for 2 × 2 tables and properties that do not depend on the marginal distributions. Psychometrika 2008; 73(4): 777– 789.
Štítky
Dětská neurologie Neurochirurgie NeurologieČlánek vyšel v časopise
Česká a slovenská neurologie a neurochirurgie

2015 Číslo 3
Nejčtenější v tomto čísle
- Addenbrookský kognitivní test – orientační normy pro českou populaci
- Míšní šok – od patofyziologie ke klinickým projevům
- Diagnostika epileptických záchvatů
- Vzduchová embolie mozku – kazuistika